Abstract
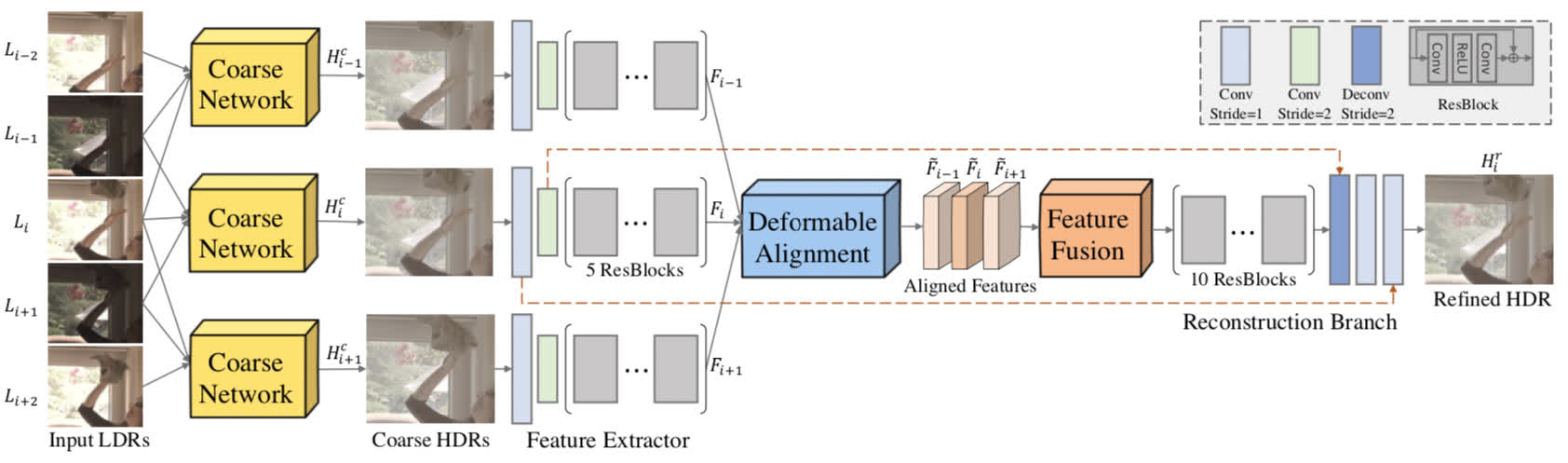
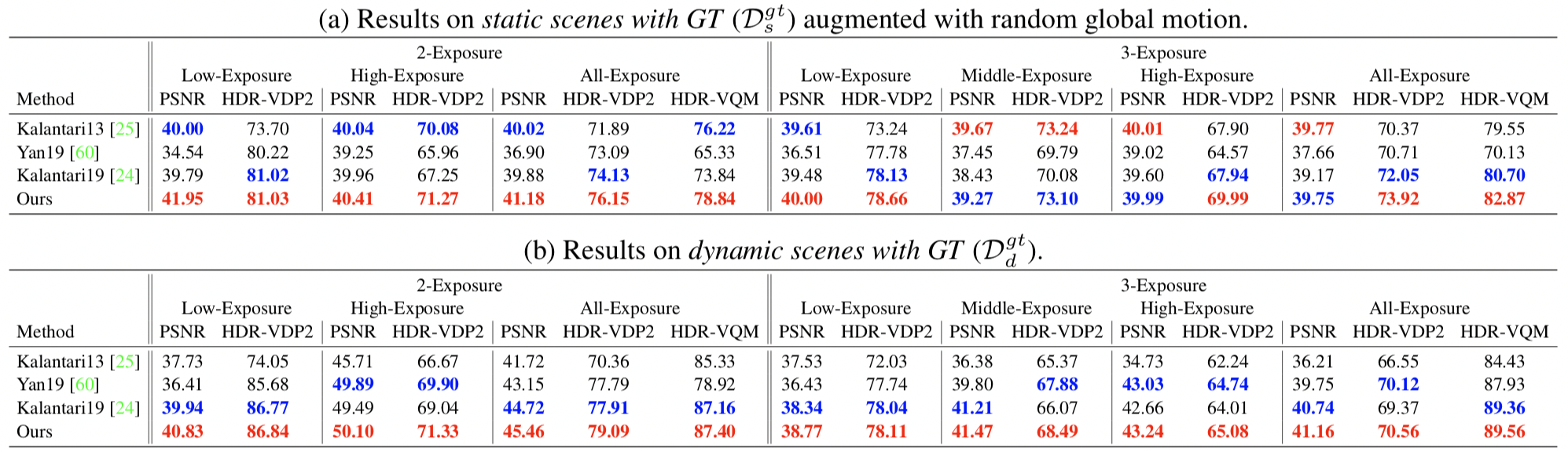
High dynamic range (HDR) video reconstruction from sequences captured with alternating exposures is a very challenging problem. Existing methods often align low dynamic range (LDR) input sequence in the image space using optical flow, and then merge the aligned images to produce HDR output. However, accurate alignment and fusion in the image space are difficult due to the missing details in the over-exposed regions and noise in the under-exposed regions, resulting in unpleasing ghosting artifacts. To enable more accurate alignment and HDR fusion, we introduce a coarse-to-fine deep learning framework for HDR video reconstruction. Firstly, we perform coarse alignment and pixel blending in the image space to estimate the coarse HDR video. Secondly, we conduct more sophisticated alignment and temporal fusion in the feature space of the coarse HDR video to produce better reconstruction. Considering the fact that there is no publicly available dataset for quantitative and comprehensive evaluation of HDR video reconstruction methods, we collect such a benchmark dataset, which contains 97 sequences of static scenes and 184 testing pairs of dynamic scenes. Extensive experiments show that our method outperforms previous state-of-the-art methods.