

| Guanying Chen1 Kai Han2 Boxin Shi3,4 Yasuyuki Matsushita5 Kwan-Yee K. Wong1 |
|
1The University of Hong Kong 2University of Oxford 3Peking University 4Peng Cheng Laboratory 5Osaka University |
|
|
|
|
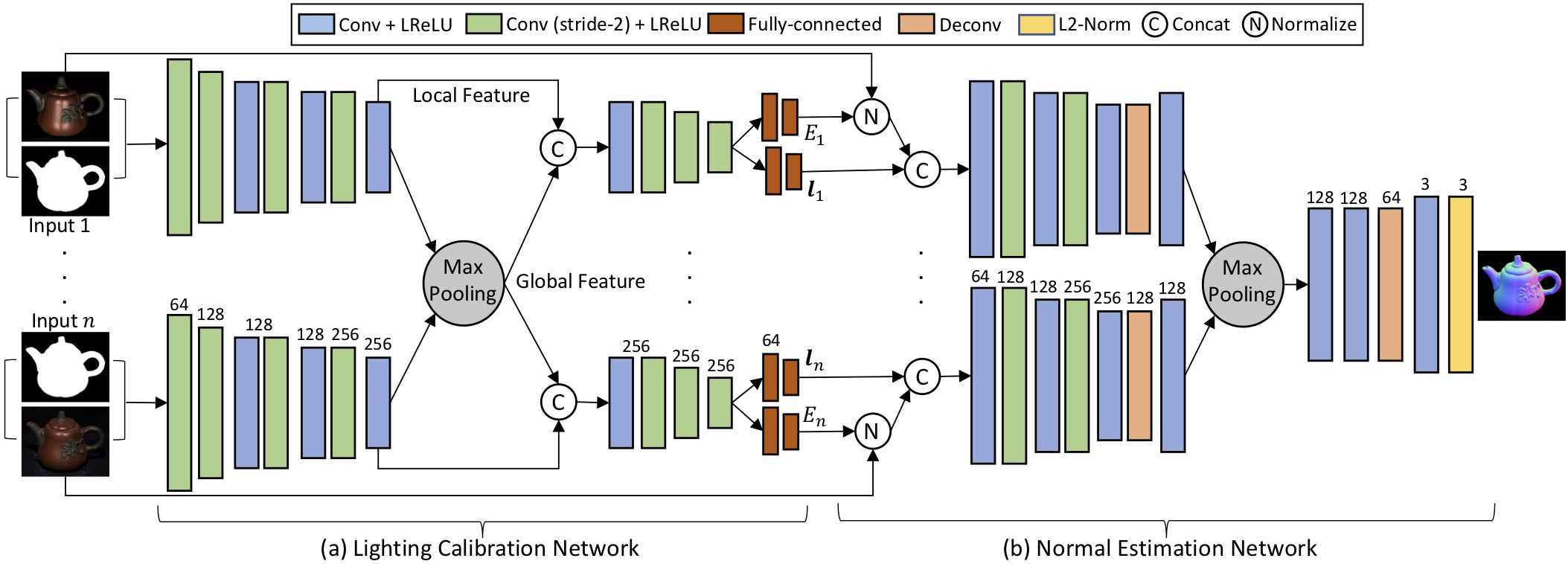
|
|
|

|
|
|
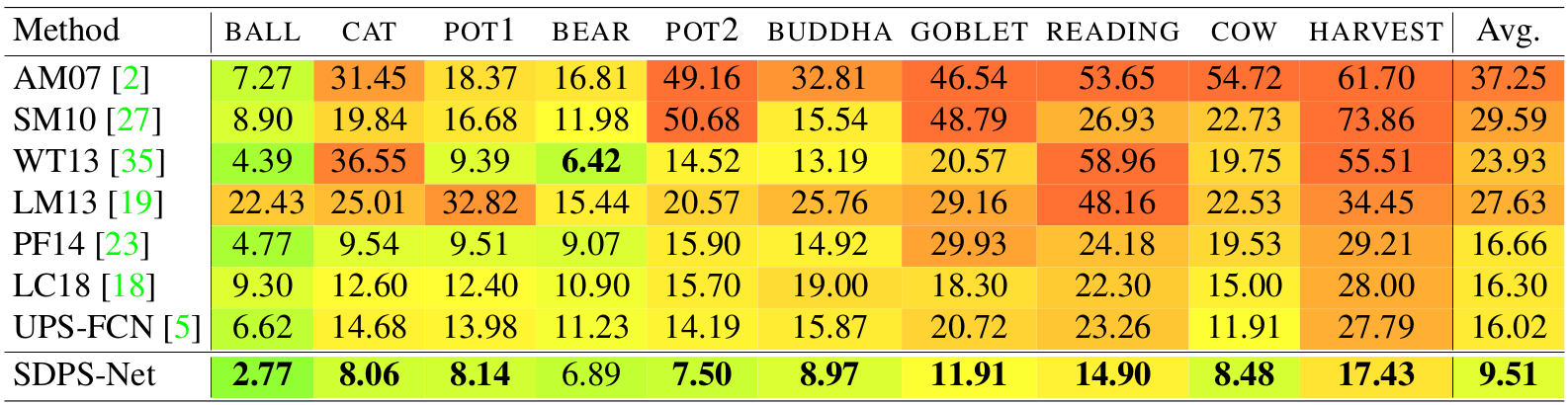
|
|
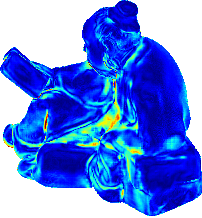
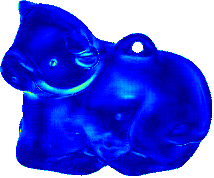
Up to Down: Sample Input, Object, GT Normal, Results of SDPS-Net, and Error Map 








|










|









|










|







|
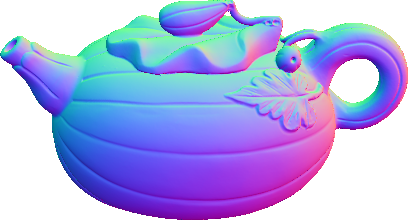
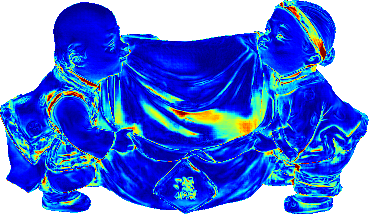
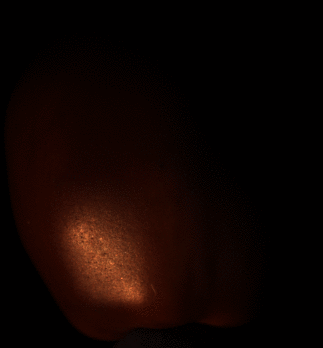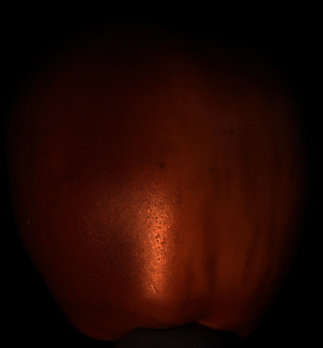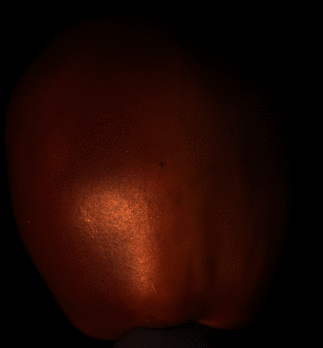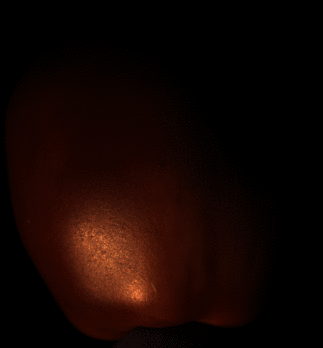
Up to Down: Sample Input, Object, Results of SDPS-Net and UPS-FCN 





|






|






|






|
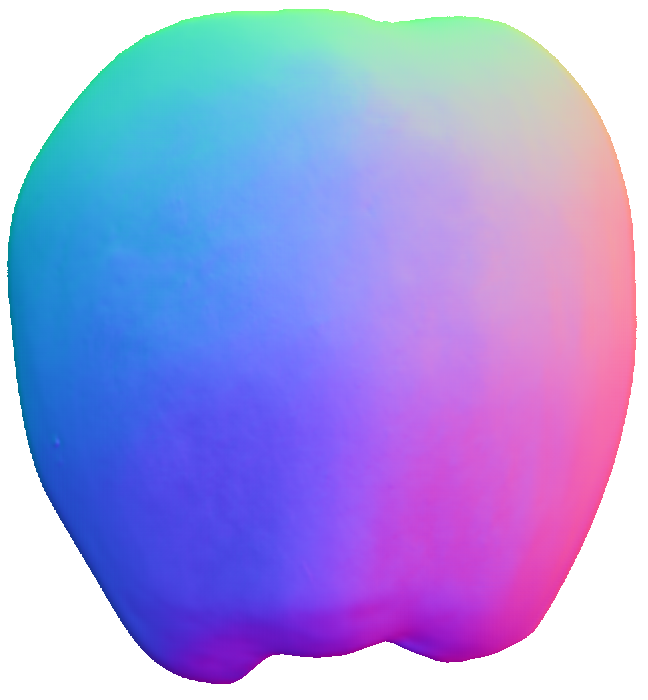




|
Acknowledgments |
Webpage template borrowed from Split-Brain Autoencoders, CVPR 2017.